Propensity Score Matcher
In this notebook, we show the basic usage of the PropensityScoreMatcher. Unlike the GeneticMatcher and ConstraintSatisfactionMatcher, the PropensityScoreMatcher does not directly optimize a particular balance score. Instead, the PropensityScoreMatcher uses the given objective as a measure of “correctness” of the propensity score model. The matcher tries a (possibly large) number of potential models and returns the model with the best score according to the given metric. In doing this, we are essentially automating an often manual process of hyperparameter optimization that accompanies propensity score matching.
We show that the hyperparameter search still leaves unoptimized balance by apply a ConstraintSatisfactionMatcher to the resulting population from the PropensityScoreMatcher. The residual unoptimzed balance highlights a major limitation of propensity score matching in general.
[1]:
import logging
logging.basicConfig(
format="%(levelname)-4s [%(filename)s:%(lineno)d] %(message)s",
level='INFO',
)
from pybalance.utils import *
from pybalance.sim import generate_toy_dataset
from pybalance.propensity import PropensityScoreMatcher, plot_propensity_score_match_distributions
from pybalance.visualization import (
plot_numeric_features,
plot_categoric_features,
plot_binary_features,
plot_joint_numeric_distributions,
plot_per_feature_loss
)
[2]:
m = generate_toy_dataset(n_pool=10000, n_target=1000, seed=123)
m
[2]:
['age', 'height', 'weight']
Headers Categoric:
['gender', 'haircolor', 'country', 'binary_0', 'binary_1', 'binary_2', 'binary_3']
Populations
['pool', 'target']
| age | height | weight | gender | haircolor | country | population | binary_0 | binary_1 | binary_2 | binary_3 | patient_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 60.807949 | 173.610298 | 77.912924 | 0.0 | 1 | 4 | pool | 0 | 0 | 1 | 1 | 0 |
| 1 | 45.810836 | 170.541198 | 112.416988 | 0.0 | 1 | 4 | pool | 0 | 1 | 0 | 0 | 1 |
| 2 | 58.876976 | 188.138610 | 108.789013 | 0.0 | 0 | 2 | pool | 0 | 0 | 1 | 1 | 2 |
| 3 | 73.398077 | 162.939196 | 65.345017 | 0.0 | 1 | 4 | pool | 0 | 1 | 1 | 1 | 3 |
| 4 | 56.890587 | 156.386701 | 78.140295 | 0.0 | 0 | 3 | pool | 0 | 0 | 1 | 0 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 995 | 39.662026 | 162.692755 | 54.607476 | 0.0 | 2 | 4 | target | 0 | 0 | 1 | 1 | 10995 |
| 996 | 49.130301 | 141.583192 | 103.798145 | 1.0 | 0 | 2 | target | 1 | 0 | 0 | 0 | 10996 |
| 997 | 68.035281 | 168.744482 | 56.499644 | 1.0 | 1 | 1 | target | 0 | 0 | 0 | 1 | 10997 |
| 998 | 62.044564 | 177.796983 | 75.983973 | 1.0 | 1 | 1 | target | 0 | 0 | 0 | 1 | 10998 |
| 999 | 51.243734 | 161.013556 | 86.513956 | 0.0 | 0 | 1 | target | 0 | 0 | 0 | 0 | 10999 |
11000 rows × 12 columns
Optimize Beta (Mean Absolute SMD)
Using the given objective function, search max_iter possible different propensity score models and take the model that gives the best match given that objective function.
[3]:
# Note that using a caliper can result in matched population being
# smaller than target! If this is undesired, do not use a caliper.
objective = beta = BetaBalance(m)
matcher = PropensityScoreMatcher(
matching_data=m,
objective=objective,
time_limit=300,
max_iter=100)
matcher.get_params()
[3]:
{'objective': 'beta',
'caliper': None,
'max_iter': 100,
'time_limit': 300,
'method': 'greedy'}
[4]:
matcher.match()
INFO [matcher.py:180] Training model LogisticRegression (iter 1/100, 0.000 min) ...
INFO [matcher.py:136] Best propensity score match found:
INFO [matcher.py:137] Model: LogisticRegression
INFO [matcher.py:139] * C: 0.023702966007283093
INFO [matcher.py:139] * fit_intercept: False
INFO [matcher.py:139] * max_iter: 500
INFO [matcher.py:139] * penalty: l2
INFO [matcher.py:139] * solver: saga
INFO [matcher.py:140] Score (beta): 0.0444
INFO [matcher.py:141] Solution time: 0.001 min
INFO [matcher.py:180] Training model SGDClassifier (iter 2/100, 0.001 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 3/100, 0.002 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 4/100, 0.003 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:136] Best propensity score match found:
INFO [matcher.py:137] Model: LogisticRegression
INFO [matcher.py:139] * C: 23.61454798133838
INFO [matcher.py:139] * fit_intercept: False
INFO [matcher.py:139] * max_iter: 500
INFO [matcher.py:139] * penalty: l1
INFO [matcher.py:139] * solver: saga
INFO [matcher.py:140] Score (beta): 0.0373
INFO [matcher.py:141] Solution time: 0.017 min
INFO [matcher.py:180] Training model LogisticRegression (iter 5/100, 0.017 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 6/100, 0.021 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 7/100, 0.022 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model LogisticRegression (iter 8/100, 0.035 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 9/100, 0.036 min) ...
INFO [matcher.py:136] Best propensity score match found:
INFO [matcher.py:137] Model: LogisticRegression
INFO [matcher.py:139] * C: 2.490445640066153
INFO [matcher.py:139] * fit_intercept: True
INFO [matcher.py:139] * max_iter: 500
INFO [matcher.py:139] * penalty: l1
INFO [matcher.py:139] * solver: saga
INFO [matcher.py:140] Score (beta): 0.0345
INFO [matcher.py:141] Solution time: 0.039 min
INFO [matcher.py:180] Training model LogisticRegression (iter 10/100, 0.039 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model LogisticRegression (iter 11/100, 0.052 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model LogisticRegression (iter 12/100, 0.065 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 13/100, 0.069 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 14/100, 0.070 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 15/100, 0.071 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 16/100, 0.072 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 17/100, 0.073 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 18/100, 0.074 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 19/100, 0.075 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 20/100, 0.077 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 21/100, 0.078 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 22/100, 0.088 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model LogisticRegression (iter 23/100, 0.098 min) ...
INFO [matcher.py:136] Best propensity score match found:
INFO [matcher.py:137] Model: LogisticRegression
INFO [matcher.py:139] * C: 0.28866833556559457
INFO [matcher.py:139] * fit_intercept: False
INFO [matcher.py:139] * max_iter: 500
INFO [matcher.py:139] * penalty: l1
INFO [matcher.py:139] * solver: saga
INFO [matcher.py:140] Score (beta): 0.0311
INFO [matcher.py:141] Solution time: 0.111 min
INFO [matcher.py:180] Training model SGDClassifier (iter 24/100, 0.111 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 25/100, 0.112 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model SGDClassifier (iter 26/100, 0.125 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 27/100, 0.126 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 28/100, 0.127 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 29/100, 0.128 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 30/100, 0.133 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 31/100, 0.134 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 32/100, 0.135 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 33/100, 0.135 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 34/100, 0.136 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 35/100, 0.137 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 36/100, 0.138 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 37/100, 0.139 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 38/100, 0.140 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 39/100, 0.156 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 40/100, 0.156 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 41/100, 0.158 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 42/100, 0.158 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 43/100, 0.159 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model LogisticRegression (iter 44/100, 0.172 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model SGDClassifier (iter 45/100, 0.186 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 46/100, 0.186 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model SGDClassifier (iter 47/100, 0.199 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 48/100, 0.200 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 49/100, 0.205 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 50/100, 0.206 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 51/100, 0.208 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 52/100, 0.209 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 53/100, 0.214 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 54/100, 0.214 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 55/100, 0.215 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 56/100, 0.216 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 57/100, 0.217 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model SGDClassifier (iter 58/100, 0.230 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 59/100, 0.231 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 60/100, 0.232 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 61/100, 0.233 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 62/100, 0.234 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 63/100, 0.234 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 64/100, 0.236 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 65/100, 0.237 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 66/100, 0.238 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 67/100, 0.239 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 68/100, 0.240 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 69/100, 0.241 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 70/100, 0.242 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:136] Best propensity score match found:
INFO [matcher.py:137] Model: LogisticRegression
INFO [matcher.py:139] * C: 0.6191810056908827
INFO [matcher.py:139] * fit_intercept: False
INFO [matcher.py:139] * max_iter: 500
INFO [matcher.py:139] * penalty: l1
INFO [matcher.py:139] * solver: saga
INFO [matcher.py:140] Score (beta): 0.0307
INFO [matcher.py:141] Solution time: 0.256 min
INFO [matcher.py:180] Training model LogisticRegression (iter 71/100, 0.256 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 72/100, 0.259 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 73/100, 0.260 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 74/100, 0.261 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model LogisticRegression (iter 75/100, 0.274 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 76/100, 0.277 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 77/100, 0.278 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 78/100, 0.279 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 79/100, 0.280 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 80/100, 0.281 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 81/100, 0.291 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model SGDClassifier (iter 82/100, 0.304 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 83/100, 0.305 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 84/100, 0.306 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 85/100, 0.307 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 86/100, 0.307 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 87/100, 0.308 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 88/100, 0.309 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 89/100, 0.310 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 90/100, 0.315 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 91/100, 0.316 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 92/100, 0.317 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 93/100, 0.318 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 94/100, 0.319 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 95/100, 0.319 min) ...
INFO [matcher.py:180] Training model LogisticRegression (iter 96/100, 0.320 min) ...
/opt/miniconda3/envs/pybalance/lib/python3.9/site-packages/sklearn/linear_model/_sag.py:350: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
INFO [matcher.py:180] Training model SGDClassifier (iter 97/100, 0.333 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 98/100, 0.334 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 99/100, 0.335 min) ...
INFO [matcher.py:180] Training model SGDClassifier (iter 100/100, 0.336 min) ...
INFO [matcher.py:136] Best propensity score match found:
INFO [matcher.py:137] Model: LogisticRegression
INFO [matcher.py:139] * C: 0.6191810056908827
INFO [matcher.py:139] * fit_intercept: False
INFO [matcher.py:139] * max_iter: 500
INFO [matcher.py:139] * penalty: l1
INFO [matcher.py:139] * solver: saga
INFO [matcher.py:140] Score (beta): 0.0307
INFO [matcher.py:141] Solution time: 0.256 min
[4]:
['age', 'height', 'weight']
Headers Categoric:
['gender', 'haircolor', 'country', 'binary_0', 'binary_1', 'binary_2', 'binary_3']
Populations
['pool', 'target']
| age | height | weight | gender | haircolor | country | population | binary_0 | binary_1 | binary_2 | binary_3 | patient_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5781 | 74.382687 | 194.082038 | 118.760023 | 0.0 | 2 | 5 | pool | 1 | 0 | 0 | 0 | 5781 |
| 6714 | 66.581290 | 178.545534 | 102.566840 | 0.0 | 2 | 2 | pool | 1 | 0 | 0 | 0 | 6714 |
| 9937 | 61.860293 | 159.449219 | 108.945960 | 0.0 | 2 | 4 | pool | 1 | 0 | 0 | 1 | 9937 |
| 8223 | 46.656414 | 140.392554 | 65.453208 | 1.0 | 2 | 4 | pool | 1 | 0 | 0 | 1 | 8223 |
| 962 | 52.829914 | 137.725077 | 93.206007 | 0.0 | 1 | 2 | pool | 1 | 1 | 0 | 0 | 962 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 995 | 39.662026 | 162.692755 | 54.607476 | 0.0 | 2 | 4 | target | 0 | 0 | 1 | 1 | 10995 |
| 996 | 49.130301 | 141.583192 | 103.798145 | 1.0 | 0 | 2 | target | 1 | 0 | 0 | 0 | 10996 |
| 997 | 68.035281 | 168.744482 | 56.499644 | 1.0 | 1 | 1 | target | 0 | 0 | 0 | 1 | 10997 |
| 998 | 62.044564 | 177.796983 | 75.983973 | 1.0 | 1 | 1 | target | 0 | 0 | 0 | 1 | 10998 |
| 999 | 51.243734 | 161.013556 | 86.513956 | 0.0 | 0 | 1 | target | 0 | 0 | 0 | 0 | 10999 |
2000 rows × 12 columns
[5]:
%matplotlib inline
plot_propensity_score_match_distributions(matcher)
[5]:
<seaborn.axisgrid.FacetGrid at 0x7f8730ed4bb0>
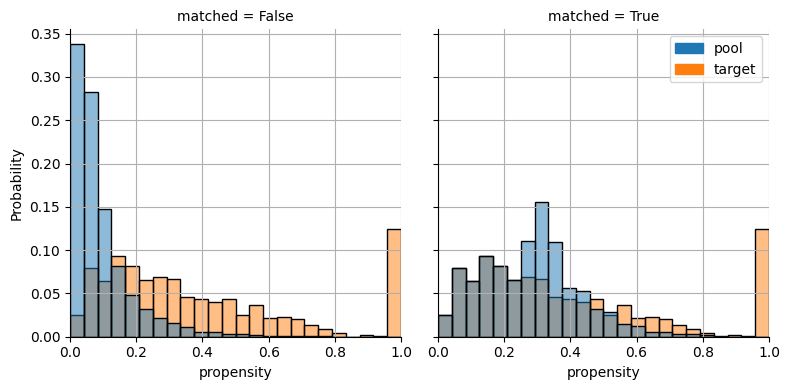
[6]:
%matplotlib inline
objective = beta = BetaBalance(m)
match = matcher.get_best_match()
m_data = m.copy().get_population('pool')
m_data.loc[:, 'population'] = m_data['population'] + ' (prematch)'
match.append(m_data)
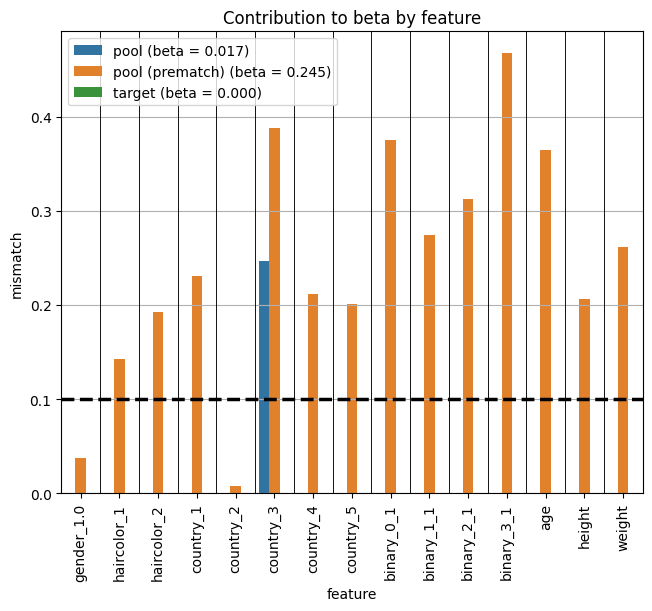
fig = plot_per_feature_loss(match, beta, 'target', debin=False)
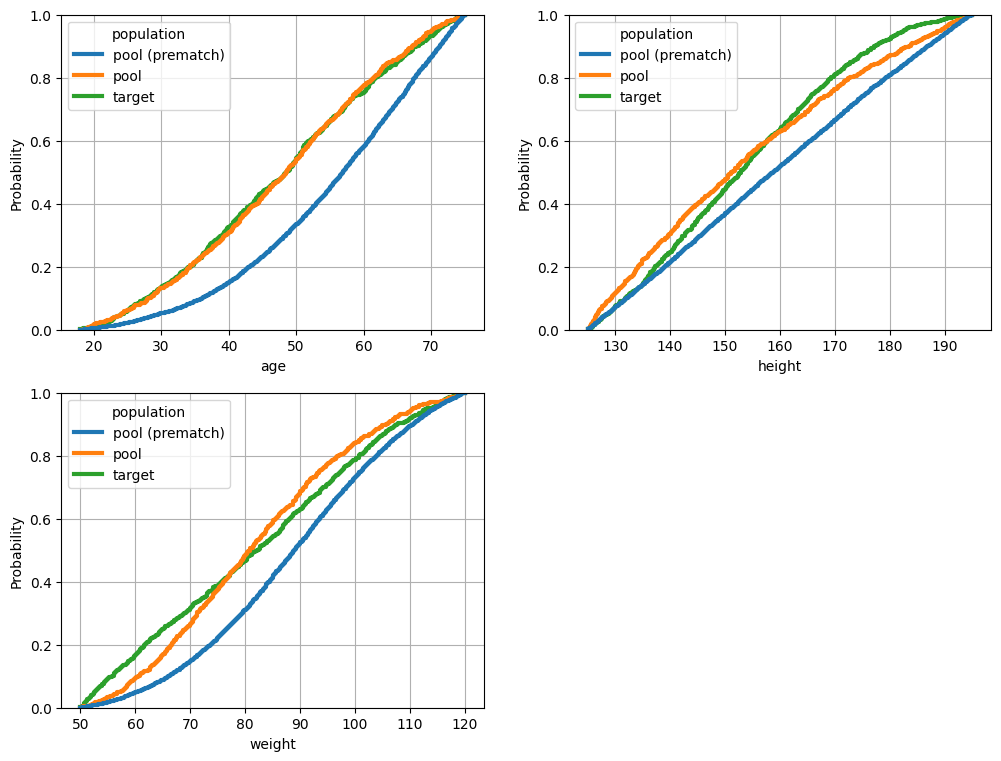
fig = plot_numeric_features(match, hue_order=['pool (prematch)', 'pool', 'target', ])
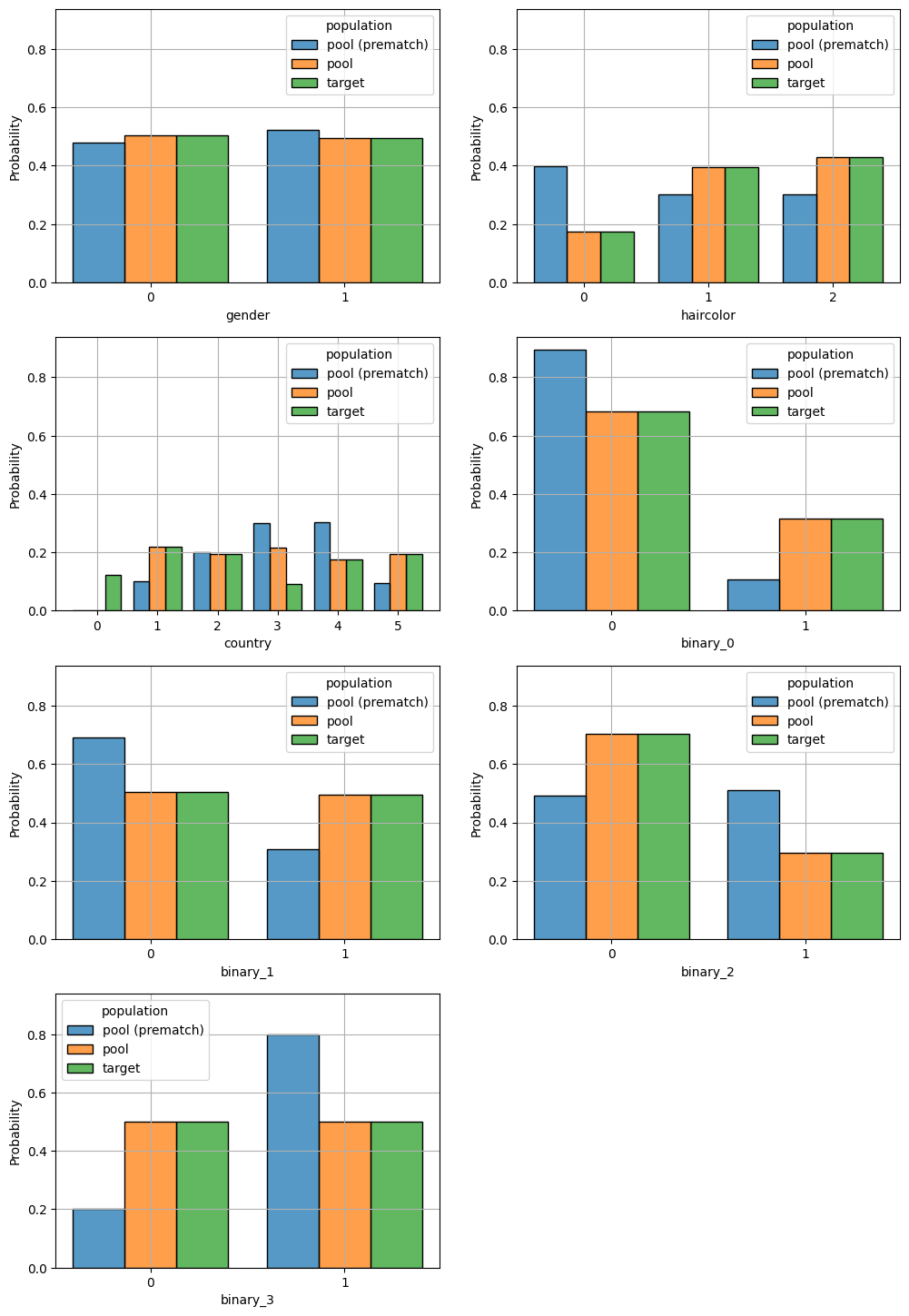
fig = plot_categoric_features(match, hue_order=['pool (prematch)', 'pool', 'target'])
INFO [matcher.py:136] Best propensity score match found:
INFO [matcher.py:137] Model: LogisticRegression
INFO [matcher.py:139] * C: 0.6191810056908827
INFO [matcher.py:139] * fit_intercept: False
INFO [matcher.py:139] * max_iter: 500
INFO [matcher.py:139] * penalty: l1
INFO [matcher.py:139] * solver: saga
INFO [matcher.py:140] Score (beta): 0.0307
INFO [matcher.py:141] Solution time: 0.256 min
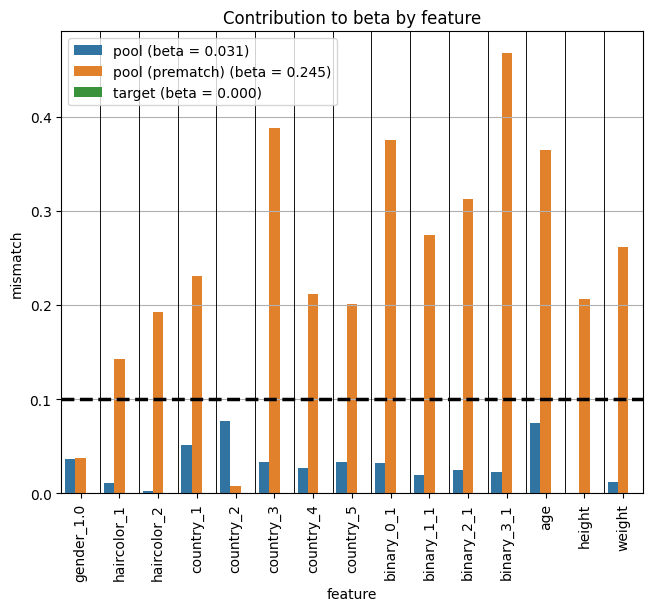
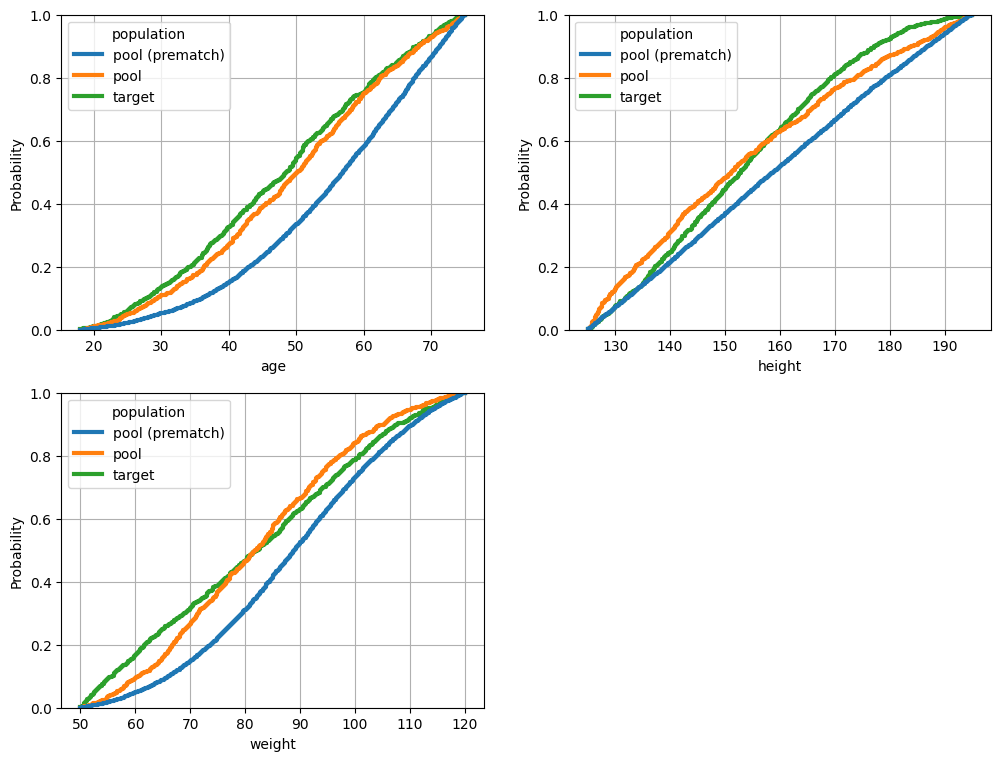
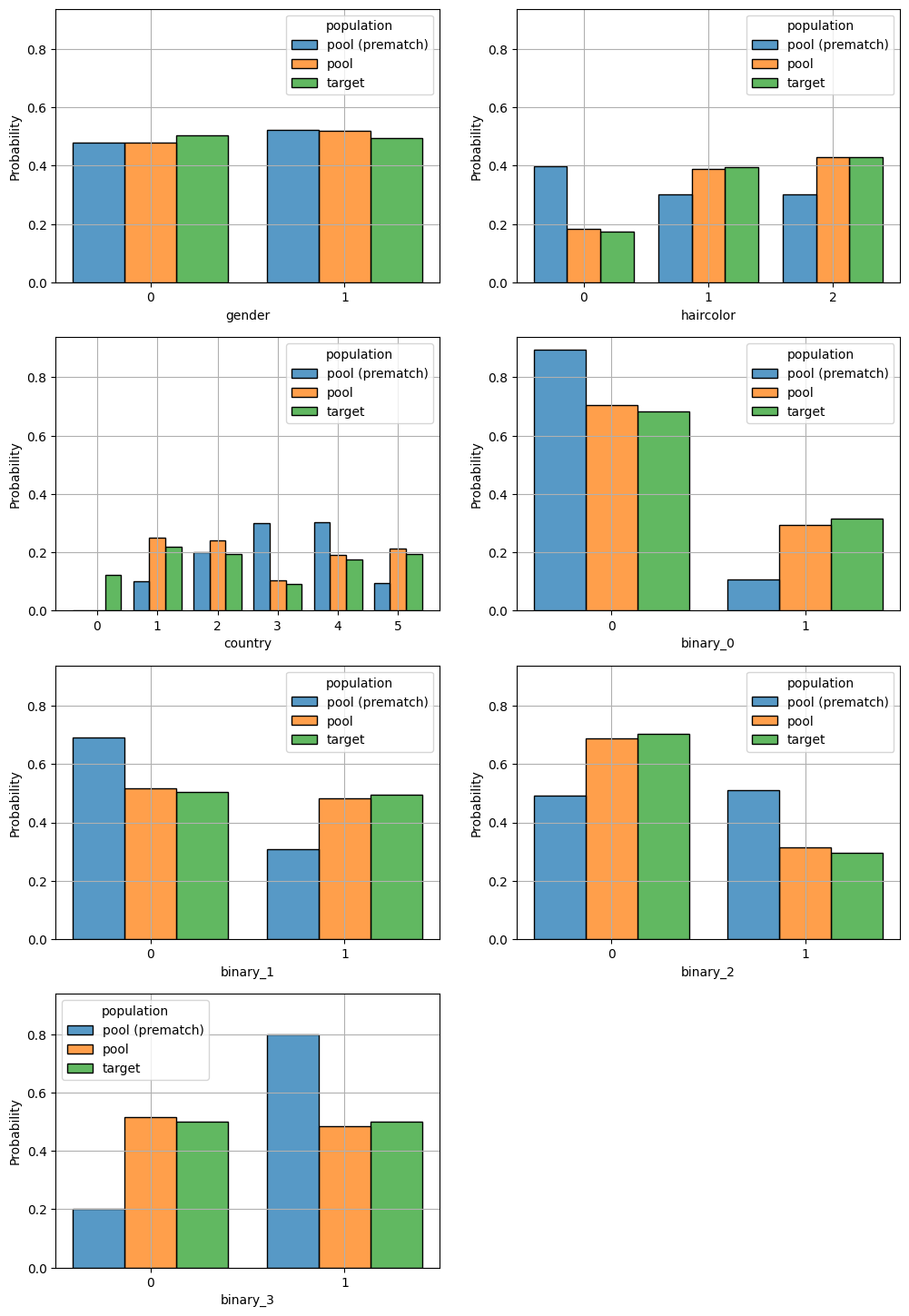
Improve upon PropensityScoreMatcher solution with ConstraintSatisfactionMatcher
Because the PropensityScoreMatcher doesn’t directly optimize balance, it only achieves good balance when we find the right propensity score model. Depending on how we’ve parameterized the space of possible propensity score models, we may in fact never find the right model. This leaves us often with residual confounding that cannot be removed via propensity score matching. Here we show that the ConstraintSatisfactionMatcher is able to find a significantly better matched solution compared to the propensity score approach.
[7]:
from pybalance.lp import ConstraintSatisfactionMatcher
matcher = ConstraintSatisfactionMatcher(
m,
time_limit=300,
objective=objective,
ps_hinting=False,
num_workers=4)
matcher.get_params()
INFO [matcher.py:65] Scaling features by factor 240.00 in order to use integer solver with <= 0.2898% loss.
[7]:
{'objective': 'beta',
'pool_size': 1000,
'target_size': 1000,
'max_mismatch': None,
'time_limit': 300,
'num_workers': 4,
'ps_hinting': False,
'verbose': True}
[8]:
matcher.match()
INFO [matcher.py:411] Solving for match population with pool size = 1000 and target size = 1000 subject to None balance constraint.
INFO [matcher.py:414] Matching on 15 dimensions ...
INFO [matcher.py:421] Building model variables and constraints ...
INFO [matcher.py:430] Calculating bounds on feature variables ...
INFO [matcher.py:520] Applying size constraints on pool and target ...
INFO [matcher.py:604] Solving with 4 workers ...
INFO [matcher.py:90] Initial balance score: 0.2449
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 1, time = 0.02 m
INFO [matcher.py:101] Objective: 480270000.0
INFO [matcher.py:120] Balance (beta): 0.2421
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 2, time = 0.04 m
INFO [matcher.py:101] Objective: 479744000.0
INFO [matcher.py:120] Balance (beta): 0.2418
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 3, time = 0.04 m
INFO [matcher.py:101] Objective: 479679000.0
INFO [matcher.py:120] Balance (beta): 0.2418
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 4, time = 0.07 m
INFO [matcher.py:101] Objective: 479629000.0
INFO [matcher.py:120] Balance (beta): 0.2417
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 5, time = 0.08 m
INFO [matcher.py:101] Objective: 479552000.0
INFO [matcher.py:120] Balance (beta): 0.2417
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 6, time = 0.09 m
INFO [matcher.py:101] Objective: 479486000.0
INFO [matcher.py:120] Balance (beta): 0.2416
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 7, time = 0.09 m
INFO [matcher.py:101] Objective: 479423000.0
INFO [matcher.py:120] Balance (beta): 0.2416
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 8, time = 0.11 m
INFO [matcher.py:101] Objective: 29842000.0
INFO [matcher.py:120] Balance (beta): 0.0165
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 9, time = 0.13 m
INFO [matcher.py:101] Objective: 29840000.0
INFO [matcher.py:120] Balance (beta): 0.0166
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 10, time = 0.15 m
INFO [matcher.py:101] Objective: 29819000.0
INFO [matcher.py:120] Balance (beta): 0.0165
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 11, time = 0.19 m
INFO [matcher.py:101] Objective: 29801000.0
INFO [matcher.py:120] Balance (beta): 0.0165
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 12, time = 0.21 m
INFO [matcher.py:101] Objective: 29777000.0
INFO [matcher.py:120] Balance (beta): 0.0140
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 13, time = 0.43 m
INFO [matcher.py:101] Objective: 29771000.0
INFO [matcher.py:120] Balance (beta): 0.0140
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 14, time = 0.72 m
INFO [matcher.py:101] Objective: 29767000.0
INFO [matcher.py:120] Balance (beta): 0.0136
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 15, time = 1.01 m
INFO [matcher.py:101] Objective: 29766000.0
INFO [matcher.py:120] Balance (beta): 0.0136
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 16, time = 1.79 m
INFO [matcher.py:101] Objective: 29764000.0
INFO [matcher.py:120] Balance (beta): 0.0140
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:96] =========================================
INFO [matcher.py:97] Solution 17, time = 2.61 m
INFO [matcher.py:101] Objective: 29763000.0
INFO [matcher.py:120] Balance (beta): 0.0165
INFO [matcher.py:125] Patients (pool): 1000
INFO [matcher.py:126] Patients (target): 1000
INFO [matcher.py:140]
INFO [matcher.py:611] Status = FEASIBLE
INFO [matcher.py:612] Number of solutions found: 17
[8]:
['age', 'height', 'weight']
Headers Categoric:
['gender', 'haircolor', 'country', 'binary_0', 'binary_1', 'binary_2', 'binary_3']
Populations
['pool', 'target']
| age | height | weight | gender | haircolor | country | population | binary_0 | binary_1 | binary_2 | binary_3 | patient_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 37.519341 | 178.337875 | 57.424543 | 0.0 | 1 | 4 | target | 1 | 1 | 1 | 1 | 10000 |
| 1 | 23.722325 | 128.347114 | 102.183004 | 0.0 | 2 | 2 | target | 0 | 1 | 0 | 1 | 10001 |
| 2 | 64.523502 | 144.600598 | 90.061948 | 1.0 | 2 | 4 | target | 1 | 0 | 0 | 1 | 10002 |
| 3 | 25.377578 | 177.986337 | 82.076883 | 0.0 | 0 | 2 | target | 1 | 0 | 0 | 1 | 10003 |
| 4 | 26.922515 | 155.633760 | 76.929413 | 1.0 | 2 | 5 | target | 1 | 1 | 0 | 1 | 10004 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 9961 | 51.638489 | 145.531672 | 56.577659 | 1.0 | 2 | 1 | pool | 0 | 0 | 1 | 0 | 9961 |
| 9975 | 67.215985 | 132.431033 | 60.001705 | 0.0 | 1 | 3 | pool | 0 | 1 | 1 | 1 | 9975 |
| 9977 | 56.680409 | 172.400095 | 100.905653 | 0.0 | 2 | 2 | pool | 1 | 0 | 1 | 1 | 9977 |
| 9983 | 65.077128 | 175.593470 | 75.612613 | 0.0 | 2 | 4 | pool | 1 | 1 | 0 | 1 | 9983 |
| 9993 | 62.762447 | 136.674765 | 69.491786 | 0.0 | 1 | 1 | pool | 0 | 0 | 0 | 1 | 9993 |
2000 rows × 12 columns
As one can already see from the reported balance metric, the ConstraintSatificationMatcher finds a much better solution. We also confirm this result visually below.
[9]:
%matplotlib inline
match = matcher.get_best_match()
m_data = m.copy().get_population('pool')
m_data.loc[:, 'population'] = m_data['population'] + ' (prematch)'
match.append(m_data)
fig = plot_per_feature_loss(match, beta, 'target', debin=False)
fig = plot_numeric_features(match, hue_order=['pool (prematch)', 'pool', 'target', ])
fig = plot_categoric_features(match, hue_order=['pool (prematch)', 'pool', 'target'])
[ ]: